
Adventures in Narrated Reality
New forms & interfaces for written language, enabled by machine intelligence
By Ross Goodwin
In May 2015, Stanford PhD student Andrej Karpathy wrote a blog post entitled The Unreasonable Effectiveness of Recurrent Neural Networks and released a code repository called Char-RNN. Both received quite a lot of attention from the machine learning community in the months that followed, spurring commentary and a number of response posts from other researchers.
I remember reading these posts early last summer. Initially, I was somewhat underwhelmed—as at least one commentator pointed out, much of the generated text that Karpathy chose to highlight did not seem much better than results one might expect from high order character-level Markov chains.
Here is a snippet of Karpathy’s Char-RNN generated Shakespeare:
KING LEAR:
O, if you were a feeble sight, the courtesy of your law,
Your sight and several breath, will wear the gods
With his heads, and my hands are wonder’d at the deeds,
So drop upon your lordship’s head, and your opinion
Shall be against your honour.
And here is a snippet of generated Shakespeare from a high order character-level Markov chain, via the post linked above:
First Citizen:
Nay, then, that was hers,
It speaks against your other service:
But since the youth of the circumstance be spoken:
Your uncle and one Baptista’s daughter.
So I was discouraged. And without access to affordable GPUs for training recurrent neural networks, I continued to experiment with Markov chains, generative grammars, template systems, and other ML-free solutions for generating text.
In December, New York University was kind enough to grant me access to their High Performance Computing facilities. I began to train my own recurrent neural networks using Karpathy’s code, and I finally discovered the quasi-magical capacities of these machines. Since then, I have been training a collection of recurrent neural network models for my thesis project at NYU, and exploring possibilities for devices that could enable such models to serve as expressive real-time narrators in our everyday lives.
An Introduction
At this point, since this is my very first Medium post, perhaps I should introduce myself: my name is Ross Goodwin, I’m a graduate student at NYU ITP in my final semester, and computational creative writing is my personal obsession.

Before I began my studies at ITP, I was a political ghostwriter. I graduated from MIT in 2009 with a B.S. degree in Economics, and during my undergraduate years I had worked on Barack Obama’s 2008 Presidential campaign. At the time, I wanted to be a political speechwriter, and my first job after graduation was a Presidential Writer position at the White House. In this role, I wrote Presidential Proclamations, which are statements of national days, weeks, and months of things—everything from Thanksgivingand African American History Month to lesser known observances like Safe Boating Week. It was a very strange job, but I thoroughly enjoyed it.
This was a rather dark time in my life, as I rapidly found myself writing for a variety of unsavory clients and causes in order to pay my rent every month. In completing these assignments, I began to integrate algorithms into my writing process to improve my productivity. (At the time, I didn’t think about these techniques as algorithmic, but it’s obvious in retrospect.) For example, if I had to write 12 letters, I’d write them in a spreadsheet with a paragraph in each cell. Each letter would exist in a column, and I would write across the rows—first I’d write all the first paragraphs as one group, then all the second paragraphs, then all the thirds, and so on. If I had to write a similar group of letters the next day for the same client, I would use an Excel macro to randomly shuffle the cells, then edit the paragraphs for cohesion and turn the results in as an entirely new batch of letters.

Writing this way, I found I could complete an 8-hour day of work in about 2 hours. I used the rest of my time to work on a novel that’s still not finished (but that’s a story for another time). With help from some friends, I turned the technique into a game we called The Diagonalization Argument after Georg Cantor’s 1891 mathematical proof of the same name.
In early 2014, a client asked me to write reviews of all the guides available online to learn the Python programming language. One guide stood out above all others, in the sheer number of times I saw users reference it on various online forums and in the countless glowing reviews it had earned across the Internet: Learn Python the Hard Way by Zed Shaw
So, to make my reviews better, I decided I might as well try to learn Python. My past attempts at learning to code had failed due to lack of commitment, lack of interest, or lack of a good project to get started. But this time was different somehow—Zed’s guide worked for me, and just like that I found myself completely and hopelessly addicted to programming.
As a writer, I gravitated immediately to the broad and expanding world of natural language processing and generation. My first few projects were simple poetry generators. And once I moved to New York City and started ITP, I discovered a local community of likeminded individuals leveraging computation to produce and enhance textual work. I hosted a Code Poetry Slam in November 2014 and began attending Todd Anderson’s monthly WordHack events at Babycastles.

In early 2015, I developed and launched word.camera, a web app and set of physical devicesthat use the Clarifai API to tag images with nouns, ConceptNetto find related words, and a template system to string the results together into descriptive (though often bizarre) prosepoems related to the captured photographs. The project was about redefining the photographic experience, and it earned more attention than I expected [1,2,3]. In November, I was invited to exhibit this work at IDFA DocLab in Amsterdam.
At that point, it became obvious that word.camera (or some extension thereof) would become my ITP thesis project. And while searching for ways to improve its output, I began to experiment with training my own neural networks rather than using those others had trained via APIs.
Training Regimen
As I mentioned above, I started using NYU’s High Performance Computing facilities in December. This supercomputing cluster includes a staggering array of computational resources — in particular, at least 32 Nvidia Tesla K80 GPUs, each with 24 GB of GPU memory. While GPUs aren’t strictly requiredto train deep neural networks, the massively parallel processes involved make them all but a necessity for training a larger model that will perform well in a reasonable amount of time.

Using two of Andrej Karpathy’s repositories, NeuralTalk2 and Char-RNN respectively, I trained an image captioning model and a number of models for generating text. As a result of having free access to the largest GPUs in the world, I was able to start training very large models right away.
NeuralTalk2 uses a convolutional neural network to classify images, then transfers that classification data to a recurrent neural network that generates a brief caption. For my first attempt at training a NeuralTalk2 model, I wanted to do something less traditional than simply captioning images.
In my opinion, the idea of machine “image captioning” is problematic because it’s so limited in scope. Fundamentally, a machine that can caption images is a machine that can describe or relate to what it sees in a highly intelligent way. I do understand that image captioning is an important benchmark for machine intelligence. However, I also believe that thinking such a machine’s primary use case will be to replace human image captioning represents a highly restrictive and narrow point of view.
So I tried training a model on frames and corresponding captions from every episode of the TV show The X-Files. My idea was to create a model that, if given an image, would generate a plausible line of dialogue from what it saw.
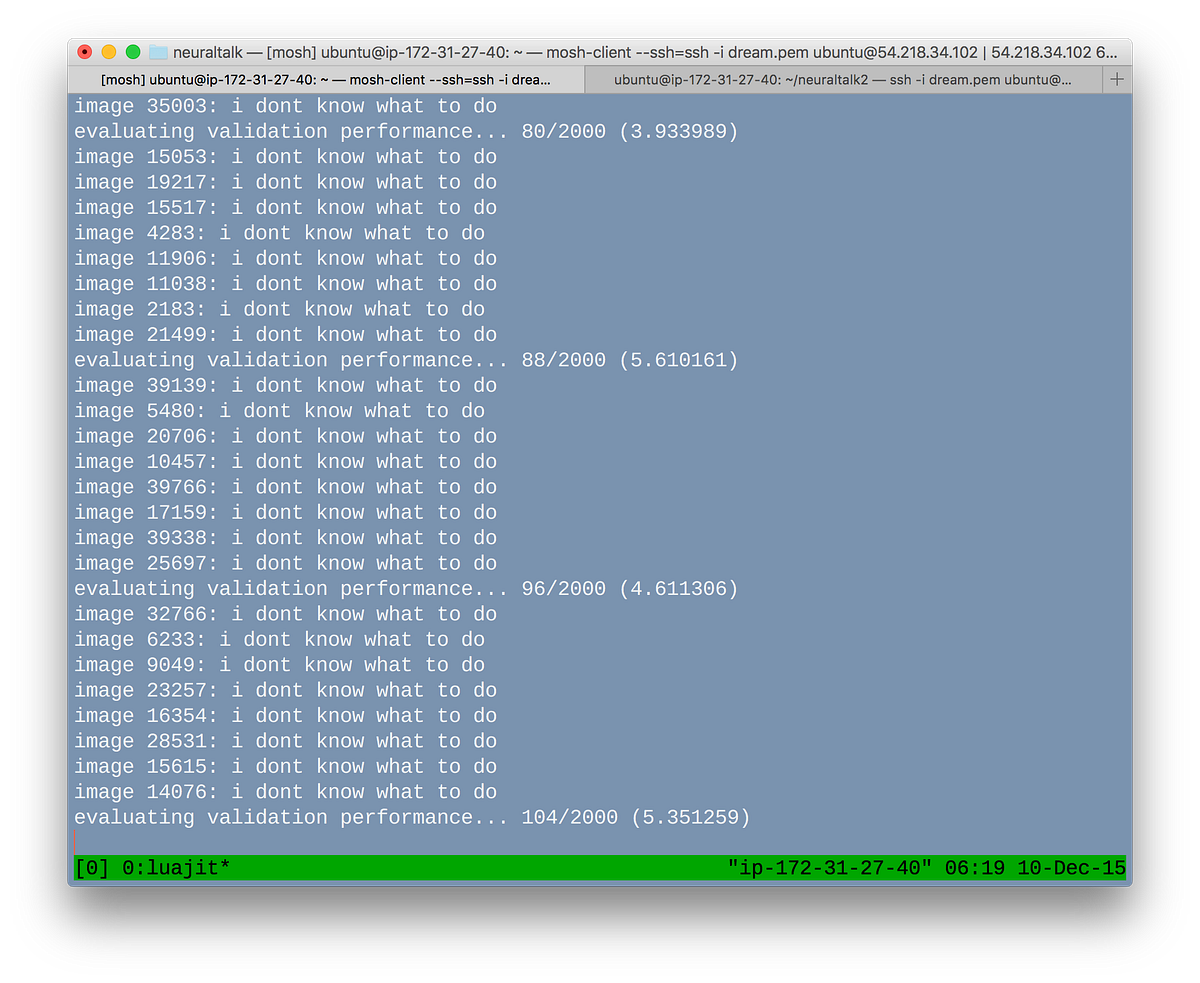
Unfortunately, it simply did not work—most likely due to the dialogue for a particular scene bearing no direct relationship to that scene’s imagery. Rather than generating a different line of dialogue for different images, the machine seemed to want to assign the same line to every image indiscriminately.
Strangely, these repetitive lines tended to say things like I don’t know, I’m not sure what you want, and I don’t know what to do. (One of my faculty advisors, Patrick Hebron, jokingly suggested this may be a sign of metacognition—needless to say, I was slightly creeped out but excited to continue these explorations.)
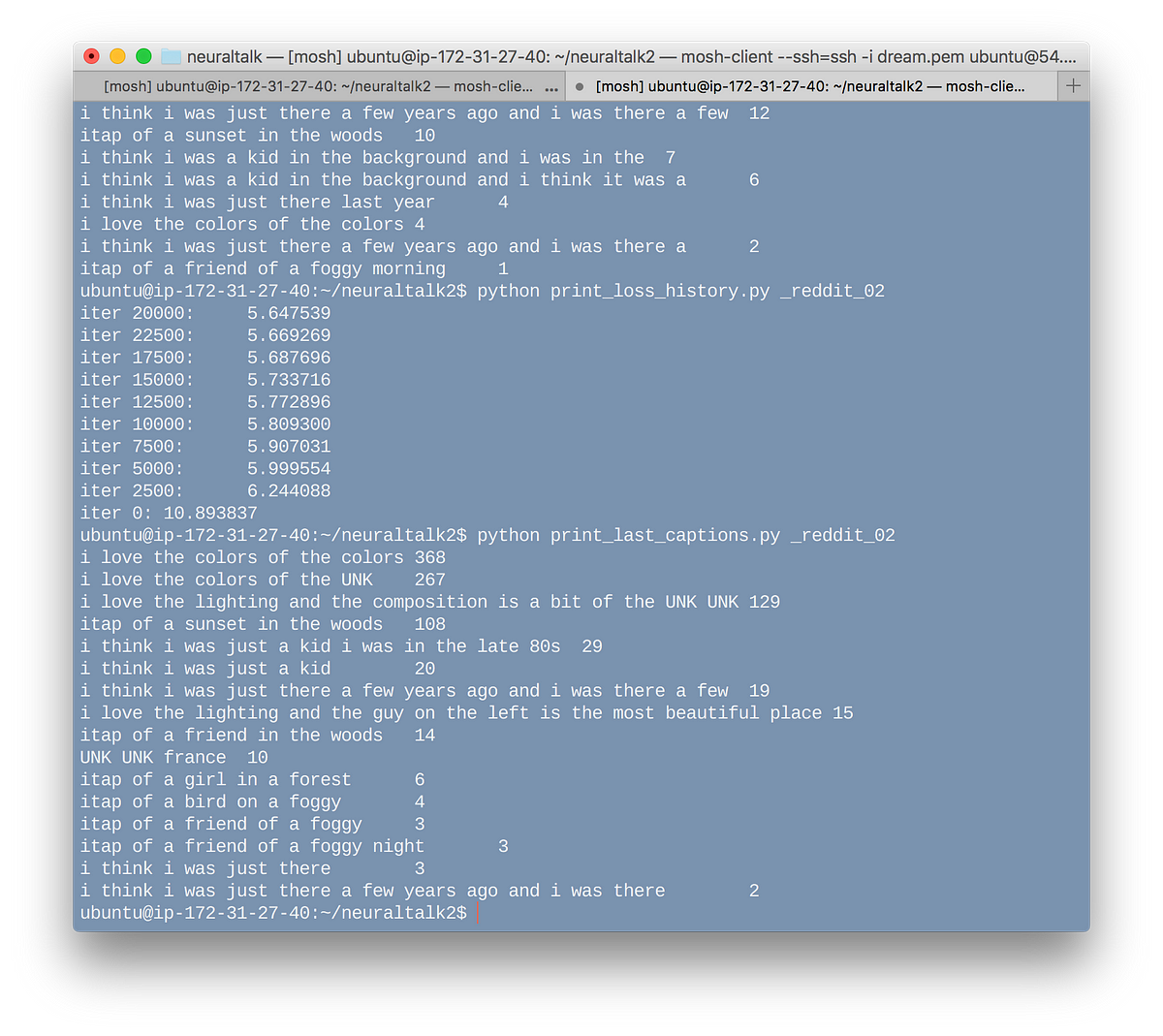
I tried two other less-than-traditional approaches with NeuralTalk2: training on Reddit image posts and corresponding comments, and training on pictures of recreational drugs and corresponding Erowid experience reports. Both worked better than my X-Files experiment, but neither produced particularly interesting results.
So I resigned myself to training a traditional image captioning model using the Microsoft Common Objects in Context (MSCOCO) caption set. In terms of objects represented, MSCOCO is far from exhaustive, but it does contain over 120,000 images with 5 captions each, which is more than I could’ve expected to produce on my own from any source. Furthermore, I figured I could always do something less traditional with such a model once trained.
I made just one adjustment to Karpathy’s default training parameters: decreased the word-frequency threshold from five to three. By default, NeuralTalk2 ignores any word that appears fewer than five times in the caption corpus it trains on. I guessed that reducing this threshold would result in some extra verbosity in the generated captions, possibly at the expense of accuracy, as a more verbose model might describe details that were not actually present in an image. However, after about five days of training, I had produced a model that exceeded 0.9 CIDErin tests, which is about as good as Karpathy suggested the model could get in his documentation.
Training Montage
As opposed to NeuralTalk2, which is designed to caption images, Karpathy’s Char-RNN employs a character-level LSTM recurrent neural network simply for generating text. A recurrent neural network is fundamentally a linear pattern machine. Given a character (or set of characters) as a seed, a Char-RNN model will predict which character would come next based on what it has learned from its input corpus. By doing this again and again, the model can generate text in the same manner as a Markov chain, though its internal processes are far more sophisticated.
LSTM stands for Long Short-Term Memory, which remains a popular architecture for recurrent neural networks. Unlike a no-frills vanilla RNN, an LSTM protects its fragile underlying neural net with “gates” that determine which connections will persist in the machine’s weight matrices. (I’ve been told that others are using something called a GRU, but I have yet to investigate this architecture.)
I trained my first text generating LSTM on the same prose corpus I used for word.camera’s literary epitaphs. After about 18 hours, I was getting results like this:

This paragraph struck me as highly poetic, compared to what I’d seen in the past from a computer. The language wasn’t entirely sensical, but it certainly conjured imagery and employed relatively solid grammar. Furthermore, it was original. Originality has always been important to me in computer generated text—because what good is a generator if it just plagiarizes your input corpus? This is a major issue with high order Markov chains, but due to its more sophisticated internal mechanisms, the LSTM didn’t seem to have the same tendency.
Unfortunately, much of the prose-trained model output that contained less poetic language was also less interesting than the passage above. But given that I could produce poetic language with a prose-trained model, I wondered what results I could get from a poetry-trained model.

The output above comes from the first model I trained on poetry. I used the most readily available books I could find, mostly those of poets from the 19th century and earlier whose work had entered the public domain. The consistent line breaks and capitalization schemes were encouraging. But I still wasn’t satisfied with the language—due to the predominant age of the corpus, it seemed too ornate and formal. I wanted more modern-sounding poetic language, and so I knew I had to train a model on modern poetry.

I assembled a corpus of all the modern poetry books I could find online. It wasn’t nearly as easy as assembling the prior corpus—unfortunately, I can’t go into detail on how I got all the books for fear of being sued.
The results were much closer to what I was looking for in terms of language. But they were also inconsistent in quality. At the time, I believed this was because the corpus was too small, so I began to supplement my modern poetry corpus with select prose works to increase its size. It remains likely that this was the case. However, I had not yet discovered the seeding techniques I would later learn can dramatically improve LSTM output.

Another idea occurred to me: I could seed a poetic language LSTM model with a generated image caption to make a new, more poetic version of word.camera. Some of the initial results (see: left) were striking. I showed them to one of my mentors, Allison Parrish, who suggested that I find a way to integrate the caption throughout the poetic text, rather than just at the beginning. (I had showed her some longer examples, where the language had strayed quite far from the subject matter of the caption after a few lines.)
I thought about how to accomplish this, and settled on a technique of seeding the poetic language LSTM multiple times with the same image caption at different temperatures.
Temperature is a parameter, a number between zero and one, that controls the riskiness of a recurrent neural network’s character predictions. A low temperature value will result in text that’s repetitive but highly grammatical. Accordingly, high temperature results will be more innovative and surprising (the model may even invent its own words) while containing more mistakes. By iterating through temperature values with the same seed, the subject matter would remain consistent while the language varied, resulting in longer pieces that seemed more cohesive than anything I’d ever produced with a computer.
As I refined the aforementioned technique, I trained more LSTM models, attempting to discover the best training parameters. The performance of a neural network model is measured by its loss, which drops during training and eventually should be as close to zero as possible. A model’s loss is a statistical measurement indicating how well a model can predict the character sequences in its own corpus. During training, there are two loss figures to monitor: the training loss, which is defined by how well the model predicts the part of the corpus it’s actually training on, and the validation loss, which is defined by how well the model predicts an unknown validation sample that was removed from the corpus prior to training.
The goal of training a model is to reduce its validation loss as much as possible, because we want a model that accurately predicts unknown character sequences, not just those it’s already seen. To this end, there are a number of parameters to adjust, among which are:
- learning rate & learning rate decay: Determines how quickly a model will attempt to learn new information. If set too low or too high, the model will never reach its optimal state. This is further complicated by the learning rate’s variable nature—one must consider not only the optimal initial learning rate, but also how much and how often to decay that rate.
- dropout: Introduced by Geoffrey Hinton et al. Forces a neural network to learn multiple independent representations of the same data by randomly disabling certain neurons during training at alternating intervals. The percentage of neurons disabled at any given moment in training is determined by the dropout parameter, a number between zero and one.
- neurons per layer & number of layers: The number of parameters in a recurrent neural network model is proportional to the number of artificial neurons per layer as well as the number of layers in the model, which is typically either two or three. For character-level LSTMs, the number of parameters in a model should, in general, be the same order of magnitude as the number of characters in the training corpus. So, a 50 MB corpus should require something in the neighborhood of 50 million parameters. But like other parameters, the exact number may be adjusted—Karpathy suggests always erring on the side of a model that’s too large rather than one that’s too small.
- batch size & sequence length: I’ll just let Karpathy explain this one, from his Char-RNN documentation:
The batch size specifies how many streams of data are processed in parallel at one time. The sequence length specifies the length of each stream, which is also the limit at which the gradients can propagate backwards in time. For example, if seq_length is 20, then the gradient signal will never backpropagate more than 20 time steps, and the model might not find dependencies longer than this length in number of characters.
The training process largely consists of monitoring the validation loss as it drops across model checkpoints, and monitoring the difference between training loss and validation loss. As Karpathy writes in his Char-RNN documentation:
If your training loss is much lower than validation loss then this means the network might be overfitting. Solutions to this are to decrease your network size, or to increase dropout. For example you could try dropout of 0.5 and so on.
If your training/validation loss are about equal then your model is underfitting. Increase the size of your model (either number of layers or the raw number of neurons per layer)
Writers of Writers
In January, I released my code on GitHub along with a set of trained neural network models: an image captioning model and two poetic language LSTM models. In my GitHub README, I highlighted a few results I felt were particularly strong [1,2,3,4,5]. Unlike prior versions of word.camera that mostly relied on a strong connection between the image and the output, I found that I could still enjoy the result when the image caption was totally incorrect, and there often seemed to be some other accidental (or perhaps slightly-less-than-accidental) element connecting the image to the words.
I then shifted my focus to developing a new physical prototype. With the prior version of word.camera, I believed one of the most important parts of the experience was its portability. That’s why I developed a mobile web app first, and why I ensured all the physical prototypes I built were fully portable. For the new version, I started with a physical prototype rather than a mobile web application because developing an app initially seemed infeasible due to computational requirements, though I have since thought of some possible solutions.

Since this would be a rapid prototype, I decided to use a very small messenger bag as the case rather than fabricating my own. Also, my research suggested that some of Karpathy’s code may not run on the Raspberry Pi’s ARM architecture, so I needed a slightly larger computer that would require a larger power source.
I decided to use an Intel NUCthat I powered with a backup battery for a laptop. I mounted an ELP wide angle camera to the strap, alongside a set of controls (a rotary potentiometer and a button) that communicated with the main computer via an Arduino.

Originally, I planned to dump the text output to a hacked Kindle, but ultimately decided the tactile nature of thermal printer paper would provide for a superior experience (and allow me to hand out the output on the street like I’d done with prior word.camera models). I found a large format thermal printer model with built-in batteries that uses 4″-wide paper (previous printers I’d used had taken paper half as wide), and I was able to pick up a couple of them on eBay for less than $50 each. Based on a suggestion from my friend Anthony Kesich, I decided to add an “ascii image” of the photo above the text.
In February, I was invited to speak at an art and machine learning symposium at Gray Area in San Francisco. In Amsterdam at IDFA in November, I had met Jessica Brillhart, who is a VR director on Google’s Cardboard team. In January, I began to collaborate with her and some other folks at Google on Deep Dream VR experiences with automated poetic voiceover. (If you’re unfamiliar with Deep Dream, check out this blog postfrom last summer along with the related GitHub repo and Wikipedia article.) We demonstrated these experiences at the event, which was also an auction to sell Deep Dream artwork to benefit the Gray Area Foundation.

Mike Tyka, an artist whose Deep Dream work was prominently featured in the auction, had asked me to use my poetic language LSTM to generate titles for his artwork. I had a lot of fun doing this, and I thought the titles came out well—they even earned a brief mention in the WIRED articleabout the show.
During my talk the day after the auction, I demonstrated my prototype. I walked onto the stage wearing my messenger bag, snapped a quick photo before I started speaking, and revealed the output at the end.
I would have been more nervous about sharing the machine’s poetic output in front of so many people, but the poetry had already passed what was, in my opinion, a more genuine test of its integrity: a small reading at a library in Brooklyn alongside traditional poets.

Earlier in February, I was invited to share some work at the Leonard Library in Williamsburg. The theme of the evening’s event was love and romance, so I generated several poems [1,2] from images I considered romantic. My reading was met with overwhelming approval from the other poets at the event, one of whom said that the poem I had generated from the iconic Times Square V-J Day kiss photograph by Alfred Eisenstaedt “messed [him] up” as it seemed to contain a plausible description of a flashback from the man’s perspective.
I had been worried because, as I once heard Allison Parrish say, so much commentary about computational creative writing focuses on computers replacing humans—but as anyone who has worked with computers and language knows, that perspective (which Allison summarized as “Now they’re even taking the poet’s job!”) is highly uninformed.
When we teach computers to write, the computers don’t replace us any more than pianos replace pianists—in a certain way, they become our pens, and we become more than writers. We become writers of writers.
Narrated Reality
Nietzsche, who was the first philosopher to use a typewriter, famously wrote “Our writing tools are also working on our thoughts,” which media theorist Friedrich Kittler analyzes in his book Gramophone, Film, Typewriter (p. 200):
“Our writing tools are also working on our thoughts,” Nietzsche wrote. “Technology is entrenched in our history, “ Heidegger said. But the one [Nietzsche] wrote the sentence about the typewriter on a typewriter, the other [Heidegger] described (in a magnificent old German hand) typewriters per se. That is why it was Nietzsche who initiated the transvaluation of all values with his philosophically scandalous sentence about media technology. In 1882, human beings, their thoughts, and their authorship respectively were replaced by two sexes, the text, and blind writing equipment. As the first mechanized philosopher, Nietzsche was also the last. Typescript, according to Klapheck’s painting, was called The Will to Power.
If we employ machine intelligence to augment our writing activities, it’s worth asking how such technology would affect how we think about writing as well as how we think in the general sense. I’m inclined to believe that such a transformation would be positive, as it would enable us to reach beyond our native writing capacities and produce work that might better reflect our wordless internal thoughts and notions. (I hesitate to repeat the piano/pianist analogy for fear of stomping out its impact, but I think it applies here too.)
In producing fully automated writing machines, I am only attempting to demonstrate what is possible with a machine alone. In my research, I am ultimately striving to produce devices that allow humans to work in concert with machines to produce written work. My ambition is to augment our creativity, not to replace it.
Another ambition of mine is to promote a new framework that I’ve been calling Narrated Reality. We already have Virtual Reality (VR) and Augmented Reality (AR), so it only makes sense to provide another option (NR?)—perhaps one that’s less visual and more about supplementing existing experiences with expressive narration. That way, we can enjoy our experiences while we’re having them, then revisit them later in an augmented format.
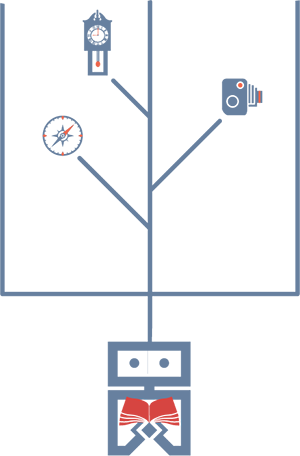
For my ITP thesis, I had originally planned to produce one general-purpose device that used photographs, GPS coordinates (supplemented with Foursquare locations), and the time to narrate everyday experiences. However, after receiving some sage advice from Taeyoon Choi, I have decided to split that project into three devices: a camera, a compass, and a clock that respectively use image, location, and time to realize Narrated Reality.
Along with designing and building those devices, I am in the process of training a library of interchangeable LSTM models in order to experience a variety of options with each device in this new space.
Uncanny Valley of Words
After training a number of models on fiction and poetry, I decided to try something different: I trained a model on the Oxford English Dictionary.
The result was better than I ever could have anticipated: an automated Balderdash player that could generate plausible definitions for made up words. I made a Twitter bot so that people could submit their linguistic inventions, and a Tumblr blog for the complete, unabridged definitions.
I was amazed by the machine’s ability to take in and parrot back strings of arbitrary characters it had never seen before, and how it often seemed to understand them in the context of actual words.
The fictional definitions it created for real words were also frequently entertaining. My favorite of these was its definition for “love”—although a prior version of the model had defined love as “past tense of leave,” which I found equally amusing.
One particularly fascinating discovery I made with this bot concerned the importance of a certain seeding technique that Kyle McDonald taught me. As discussed above, when you generate text with a recurrent neural network, you can provide a seed to get the machine started. For example, if you wanted to know the machine’s feelings on the meaning of life, you might seed your LSTM with the following text:
The meaning of life is
And the machine would logically complete your sentence based on the patterns it had absorbed from its training corpus:
The meaning of life is a perfect version of the proper form, the concept of poetry referring to the result of the possession of life and strength and pride in the accurate condition of the story and the consequences of the poem until the moment is not enough for the life of a man to find a secret of unexpected maternity.
However, to get better and more consistent results, it makes sense to prepend the seed with a pre-seed (another paragraph of text) to push the LSTM into a desired state. In practice, it’s good to use a high quality sample of output from the model you’re seeding with length approximately equal to the sequence length (see above) you set during training.
This means the seed will now look something like this:
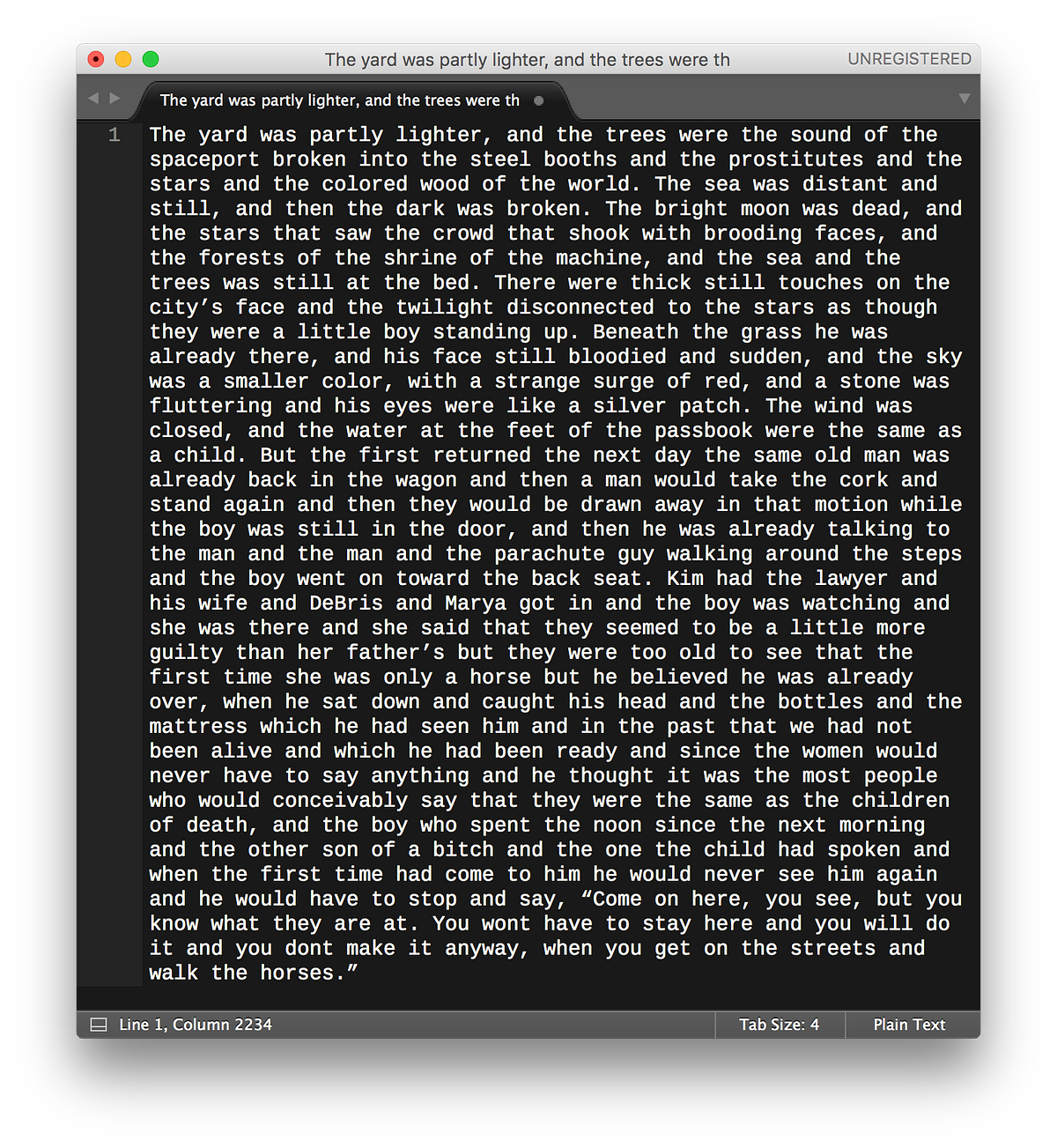
The yard was partly lighter, and the trees were the sound of the spaceport broken into the steel booths and the prostitutes and the stars and the colored wood of the world. The meaning of life is
And the raw output will look like this (though usually I remove the pre-seed when I present the output):
The yard was partly lighter, and the trees were the sound of the spaceport broken into the steel booths and the prostitutes and the stars and the colored wood of the world. The meaning of life is dead. “Yes,” said Shalom. “We must tell you. I was a real man.” “Listen,” he said. “Did you ever think of the one you were talking about?”
The difference was more than apparent when I began using this technique with the dictionary model. Without the pre-seed, the bot would usually fail to repeat an unknown word within its generated definition. With the pre-seed, it would reliably parrot back whatever gibberish it had received.
In the end, the Oxford English Dictionary model trained to a significantly lower final validation loss (< 0.75) than any other model I had trained, or have trained since. One commenter on Hacker News noted:

After considering what to do next, I decided to try integrating dictionary definitions into the prose and poetry corpora I had been training before. Additionally, another Stanford PhD student named Justin Johnson released a new and improved version of Karpathy’s Char-RNN, Torch-RNN, which promised to use 7x less memory, which would in turn allow for me to train even larger models than I had been training before on the same GPUs.
It took me an evening to get Torch-RNN working on NYU’s supercomputing cluster, but once I had it running I was immediately able to start training models four times as large as those I’d trained on before. My initial models had 20–25 million parameters, and now I was training with 80–85 million, with some extra room to increase batch size and sequence length parameters.
The results I got from the first model were stunning—the corpus was about 45% poetry, 45% prose, and 10% dictionary definitions, and the output appeared more prose-like while remaining somewhat cohesive and painting vivid imagery.
Next, I decided to train a model on Noam Chomsky’s complete works. Most individuals have not produced enough publicly available text (25–100 MB raw text, or 50–200 novels) to train an LSTM this size. Noam Chomsky is an exception, and the corpus of his writing I was able to assemble weighs in at a hefty 41.2 MB. (This project was complicated by the fact that I worked for Noam Chomsky as an undergraduate at MIT, but that’s a story for another time.) Here is a sample of the output from that model:
The problems of advanced industry are not based on its harshly democratic processes, and depend on the fact that the ideological institutions are interested in protecting them from the construction of commercial control over the population. The U.S. took over the proportion of U.S. control over the Third World that supported the level of foreign investment by the massacres of 1985, and the reaction of human rights, and a successful propaganda and the procedural result of the invasion, and the concern was demanded by the press and many others.
Unfortunately, I’ve had trouble making it say anything interesting about language, as it prefers to rattle on and on about the U.S. and Israel and Palestine. Perhaps I’ll have to train the next model on academic papers alone and see what happens.
Most recently, I’ve been training machines on movie screenplays, and getting some interesting results. If you train an LSTM on continuous dialogue, you can ask the model questions and receive plausible responses.
To be continued…
I promised myself I wouldn’t write more than 5000 words for this article, and I’ve already passed that threshold. So, rather than attempting some sort of eloquent conclusion, I’ll leave you with this brief video.
There’s much more to come in the near future. Stay tuned.
Edit 6/9/16: Check out Part II!
Read the original:
https://medium.com/artists-and-machine-intelligence/adventures-in-narrated-reality-6516ff395ba3